
How Does AI Use Existing Songs to Build New Ones?

When AI music companies say their models are “trained on songs,” they are not saying the system stores tracks, memorizes melodies, or keeps a hidden library it can pull from later.
Training is the process of exposing a model to huge amounts of audio so it can learn how music generally behaves. The system isn’t studying individual works so much as absorbing patterns across many works: how rhythm flows, how harmony resolves, how vocals tend to move, and how different sounds cluster together in styles we recognize as genres.
A helpful comparison is learning a language. You don’t memorize every sentence you’ve ever heard. You learn grammar, rhythm, tone, and probability. Training works the same way for music.
In this article, we’ll take a look at how AI music technology leverages music — whether it’s been recorded already by hit artists, or laid down in a studio by a single musician — to build the songs we enjoy making today.
How songs are turned into something a model can learn from?
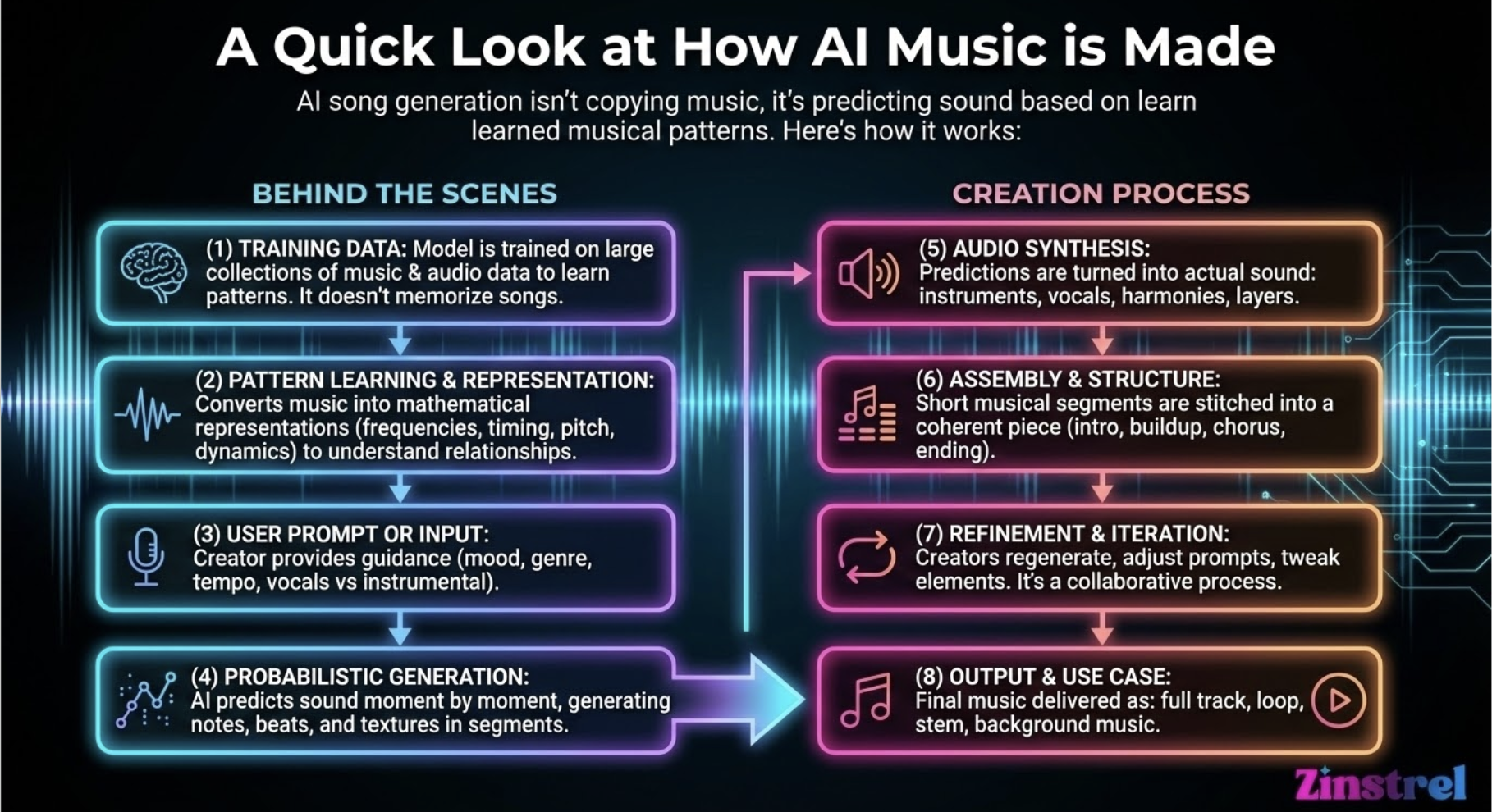
The technology starts way before any music is introduced as training data.
The first step is for the AI companies to build a framework for translating music into numbers, mathematical representations that describe things like pitch movement, timing, intensity, and tone color.
Then, once music is input for training purposes, the model doesn’t “listen” to music the way a person does. It’s seeing millions of tiny fragments and learning how they relate to one another. Which sounds tend to follow others. Which combinations feel stable. Which feel tense. Which patterns are common and which are rare.
During training, the system is repeatedly asked a simple question: based on everything you’ve seen so far, what is most likely to come next?
Over time, it builds an internal map of musical probability.
It learns that certain chord movements feel resolved, that choruses often repeat, that specific rhythmic feels suggest energy or calm. None of this is stored as a song. It’s stored as statistical tendencies. Think of it as quantum-level music theory knowledge.
Once training is complete, generation works by predicting sound step by step, not by retrieving anything from the past. There is no “play back” button for training data.
This is important: the model is not labeling songs, artists, or melodies. It’s learning relationships, not references.

So… is this copying artists?
This is where the real debate lives. There have been major lawsuits against the top AI music companies because artists believe utilizing copyrighted work to train their models presents a copyright violation. Meanwhile, some AI companies say their training data isn’t stealing because it’s just providing pattern recognition from material that’s already in the public sphere. And still, other AI companies are touting their “100% ethically sourced” training data, with music provided by artists who’ve opted in.
Here’s the debate:
The argument against calling it copying
From a technical standpoint, most modern AI music models are not copying in the literal sense. They do not contain recordings of artists’ songs, and they cannot reproduce a track unless something has gone very wrong in training or prompting.
What they produce is newly generated audio based on learned patterns. That’s why outputs can feel familiar without being traceable. The model knows how music tends to work, not how a specific song works.
Supporters argue this is no different in principle from how human musicians learn by listening to thousands of songs over time.
The argument for calling it copying
Critics point out that learning from artists’ work without permission still creates economic and cultural harm, even if the system isn’t reproducing exact songs.
If a model learns style, vocal tendencies, or genre conventions directly from working musicians (and then competes with those same musicians), some argue that functionally, the value of the original work has been extracted without consent or compensation.
In that view, the issue isn’t technical copying. It’s unlicensed learning at scale.
Both perspectives can be true depending on whether you’re talking about code or consequences.
What “we don’t train on user uploads” actually means
When companies say they don’t train on user uploads, they’re usually drawing a line between foundational training and ongoing usage.
Foundational training happens once, using large datasets to teach the model how music works. User uploads, in these cases, are treated as finished outputs — not new learning material. Your song doesn’t feed back into the system and shape future generations.
This distinction matters because it affects ownership, consent, and trust. It also explains why platforms are increasingly explicit about this policy, even if they’re still vague about what happened earlier in the process.
Can models accidentally recreate real songs?
It’s rare, but it can happen. This usually occurs when training data is too narrow, prompts are extremely specific, or the model over-relies on common melodic structures.
To prevent this, AI music systems introduce randomness, similarity checks, and constraints as part of their algorithms that push outputs away from recognizable melodies.
The goal is resemblance at the level of style, not duplication at the level of content.
Why this debate isn’t going away
When people argue about “training on songs,” they’re often arguing about different things at the same time.
Engineers are talking about probability and pattern learning. Artists are talking about labor, consent, and value. Both sides are using the same word, “training,” to describe very different concerns.
Understanding how training actually works doesn’t settle the ethical debate. But it does make the conversation clearer, and less driven by fear or misinformation.
And in a space moving this fast, clarity is power.